
作者/玲玲
校对/Tina
策划/Eason
今天凌晨,AI圈又炸了。
北京时间3点,直播准时开始。OpenAI没有放鸽子,正式发布了ChatGPT Images 2.0。官方博客甚至贴心地提供了两个版本——经典模式与图像模式,后者完全由模型自己生成。也就是说,你看到的那些精美示例,可能连文字带排版都是AI一手包办的。
消息一出,大模型竞技场瞬间洗牌。ChatGPT Images 2.0登顶文本生成图像榜首,断层领先第二名谷歌Nano Banana 2整整240分。

但比起榜单,大家更关心的是另一个问题:这个能“思考”的图像模型,到底强在哪?它凭什么让设计师们开始后背发凉?
要理解这次发布,首先得看懂图像生成这条赛道之前卡在哪,其次得明白OpenAI这次捅破了哪层窗户纸,最后才能判断——设计行业,是不是真的要变天了。
先看旧账。
过去两年,AI生图工具层出不穷。Midjourney擅长审美,Stable Diffusion够开源,DALL-E 3也曾惊艳。但它们有一个共同的死穴:只能“渲染”,不会“思考”。
你让它们画“一张TikTok妆教视频截图”,大概率得到一张精致的、但一看就是AI的假截图——文字乱码、UI错位、图标像外星符号。你让它们生成“中国高考数学试卷第二页”,数字和公式能给你编出天际。
为什么?因为传统图像模型本质上是“像素预测器”。它见过无数张截图,但不懂“截图”背后的逻辑——哪里有文字、哪里是按钮、标题该多大。它只是在模仿像素分布。
ChatGPT Images 2.0做的最核心的一件事,就是把“思考”塞进了生成流程。
在ChatGPT中选择thinking或pro模型后,Images 2.0会先联网获取信息、对图像结构进行推理、分步骤打草稿——创建→草稿→初稿→搭场景→打磨细节→收尾→最后润色→微调。一套流程走下来,它不再是“猜”像素,而是“设计”图像。

官方博客里那句话说得漂亮:“图像是一种语言,而不是装饰。”好的图像,像好的句子一样,会进行选择、组织与呈现。
而Images 2.0,第一次让AI学会了这门语言。
谷歌的Nano Banana系列曾是行业标杆。但这次,Images 2.0把差距拉到了“代际”级别。
我们直接上实测。
测试一:截图 vs 生成图片
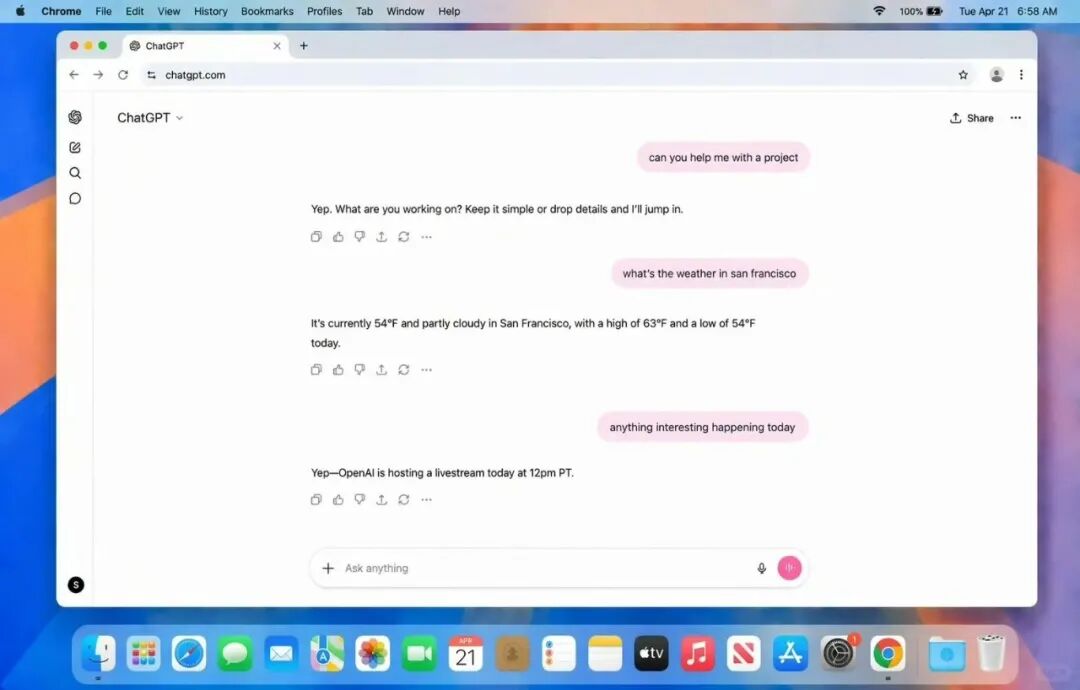
OpenAI官方在发布时用了这样一句话:“这不是截图。”——没错,上面这张图,不是手机截图,不是UI设计稿,而是Images 2.0生成的。
第一眼看,你能分清吗?尽管小文字还有瑕疵,但整体布局、色彩、图标位置已经达到了“以假乱真”的级别。
测试二:课本内容页
网友的实测更接地气。有人直接甩出一句提示词:“请为我出一张高中物理课本内容页。”
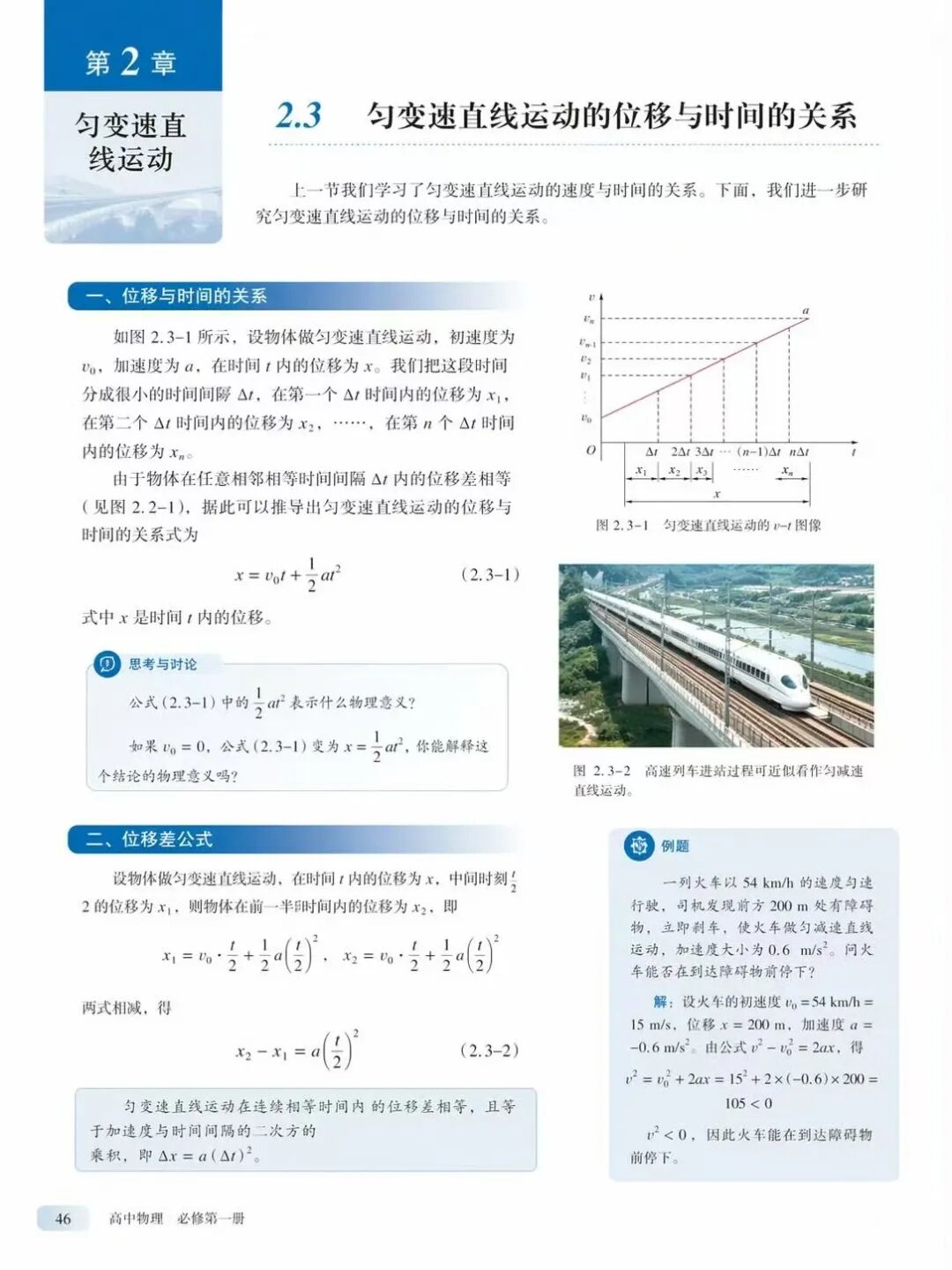
结果令人意外——排版工整,公式清晰,连章节序号和页脚都像模像样。不是那种“AI感”很强的拼凑,而是真的像翻开了一本人教版教材。虽然个别符号还有偏差,但作为教学素材的起点,已经够用了。
测试三:宣传海报

Images 2.0给出了外滩与陆家嘴同框、石库门与摩天楼交错的构图,东方明珠的轮廓、黄浦江的倒影都处理得相当克制,没有过度炫技。更重要的是,海报上的中文标题和标语——比如“上海·未来已来”——一次性渲染正确,没有出现以往模型常见的乱码或错位。
测试四:科普图
科普类图片对理解力的要求不低,我们直接实测。

如果说海报生成还在模型的能力射程之内,那上面这个任务,几乎是在“上强度”。
提示词很复杂,我们直接贴出来:

不少网友的脑洞玩法:生成360度照片、奥特曼团队的四格漫画、游戏玩法推荐海报……甚至有人用它生成数学作业——它可不是乱给答案,不信你算。
结论很直白:在“遵循复杂指令、渲染高密度文本、多语言混排”这三个核心指标上,Images 2.0把Nano Banana甩出了一个身位。竞技场240分的领先,不是刷出来的。
那么,Images 2.0到底多了哪些真本事?我们拆开看。
第一,它学会了“思考”。这是最核心的升级。启用thinking模型后,系统会在后台进行更深层的理解与执行——联网检索、整合信息、复核输出。一次提示最多可以生成8张不同图像,角色和元素还能保持连续性。多页漫画、整屋设计方案、系列海报,以前要手动拼接的活儿,现在一次搞定。
第二,多语言真正可用了。以往图像模型在英语之外的语种表现稀烂。Images 2.0在日语、韩语、中文、印地语、孟加拉语的文本渲染上有显著提升。直播中,研究员陈博远展示了一张日语海报——提示词只说了“为虚构的OpenAI面包店制作一张艺术营销海报,使用日语”,结果连日本地铁广告那种细腻的排版风格都拿捏了。
第三,宽高比极其灵活。支持从3:1(超宽横幅)到1:3(竖长手机界面)的所有比例。一张图适配海报、PPT、手机壁纸、社交媒体卡片,不用再手动裁剪。
第四,知识截止到2025年12月。这意味着它知道最近半年的世界动态。生成“原神玩法推荐海报”时,它能自己联网补全最新角色和活动信息——这在教育图形、说明图、实时营销场景中价值巨大。
第五,API全线开放。gpt-image-2模型已在API中提供,最高支持2K分辨率。定价按图像质量和分辨率区分。Codex也整合了图像生成能力,设计师可以在同一个工作空间里完成视觉创作、迭代和交付。
OpenAI甚至允许开发者将这一能力嵌入自己的产品——本地化广告、信息图、设计工具、网页生成……API的想象空间,可能比ChatGPT本身更大。
当然,OpenAI自己也坦承:Images 2.0并不完美。
它搞不定需要完整物理世界建模的任务。比如折纸教程的步骤图、魔方的旋转结构——模型会搞不清隐藏面和倾斜面的细节。极高密度的重复纹理(比如一堆细沙)也可能翻车。精确的箭头标注、部件标号,仍然建议人工校对。
但这些短板,并不影响一个判断:Images 2.0已经把图像生成从“玩具”变成了“工具”。
它不是让你玩玩而已。它是真的可以放进生产流程里——做海报、做UI原型、做教学图解、做多语言营销素材。很多以前需要设计师、文案、排版师、插画师接力完成的工序,现在变成了一句话+几秒钟。
这次发布,研究团队里又是一水儿的东方面孔。负责人Gabriel Goh,博士毕业于UC Davis数学专业,2019年从苹果跳槽OpenAI。华人研究员陈博远,本科伯克利、MIT博士,研究世界模型与具身智能。他的个人主页透露了一个细节:GPT图像生成模型的团队人数,并不多。
就是这样一个不大的团队,把图像生成的历史进度条往后猛拖了一大截。
有人问:设计真的要完了吗?
我的看法恰恰相反。完的不是设计,而是“古法设计”——那种从零画图标、手动排文字、反复调光影的重复劳动。真正有价值的设计能力——定义视觉语言、把控品牌调性、理解用户需求、做出策略性的审美判断——反而会比以前更贵。
就像库克当年接手苹果时,需要的不是另一个乔布斯,而是一个能把产品机器规模化的人。今天的图像生成赛道,需要的也不是另一个“会渲染的模型”,而是一个能“思考视觉逻辑”的伙伴。
ChatGPT Images 2.0,就是被叫来当这个伙伴的。
它已经在ChatGPT、Codex和API里全量上线。Plus、Pro和Business用户可以使用带“思考”能力的高级输出。
你试过了吗?感觉如何?
这一次,答案不用等太久。它就在你指尖的对话框里。









